 Python并发编程——多进程编程 multiprocessing 模块
Python并发编程——多进程编程 multiprocessing 模块
Python 并发编程可以分为三块:多进程编程,多线程编程,多协程编程。前两者是由于操作系统控制的,协程是由用户控制。所以在多进程的编程上,不同操作系统的效果不一样。如果是为了学习多进程编辑,建议在Mac Os 或者 Linux 上。
本篇介绍基于进程的并行操作,主要用到的模块是 multiprocessing
# 简单多进程编程
简单多进程用 Process 和 Pool 两个基础类就可以实现
# Process
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start() # 启动进程
p.join() # 阻塞进程,只有当本次进程完成后才运行下一进程。进程同步逻辑。
2
3
4
5
6
7
8
9
下面我们可以详细看看 Process 类的属性,构造方法和方法
# 构造方法
class multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
group 兼容逻辑,始终设置为None
target 目标函数
args, kwargs 传入目标函数的参数,列表参数和字典参数
name 进程名称
daemon 后台运行,守护进程。若 daemon =True,该进程会一直存在于主进程中,伴随着父进程终止而终止。
Tips: 守护进程
主进程结束后,子进程不一定会运行结束。如果我们需要让父进程终止的时候,可以设置子进程为守护进程。注意的是,守护进程不能够再创造子进程了。
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=True) # 创建Process类时设置 p.daemon = True # 主动设置deemon 属性1
2
# 属性
- pid 进程ID
- name 进程名
- deamon 设置后台守护进程
- exitcode 子进程退出代码。如果进程尚未终止,这将是
None。负值 -N 表示孩子被信号 N 终止。
我们可以轻松的通过访问任一 Process 类的变量获取基本信息
multiprocessing.current_process().pid
multiprocessing.current_process().name
2
# 方法
run() 进程活动的方法
通过重载 run 方法实现进程
import multiprocessing class MyProcess(multiprocessing.Process): def __init__(self): super().__init__() def run(self): name = multiprocessing.current_process().name pid = multiprocessing.current_process().pid print(f'name:{name}, pid:{pid}') if __name__ == '__main__': p = MyProcess() p.start() p.join()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16需要注意的是,尽管我们修改的是 run 方法。我们启动进程的方法还是 p.start
start() 启动进程
join([timeout]) 进程阻塞,直到进程终止。
timeout 是阻塞的时间,默认None,一直阻塞直到进程终止。
is_alive() 进程存在返回 True, 否则 False
terminate()/kill() 在Unix上,这是使用
SIGTERM信号完成的close() 关闭
Process对象,释放与之关联的所有资源
# Pool
如果需要运行多个子进程,采用进程池 Pool 的方式可以节省程序开销。进程的创建和销毁都是需要操作系统资源的。
# 进程池Pool vs Process
import multiprocessing
import os
def worker(msg):
print("%s is now running, process id: %s" % (msg, os.getpid()))
if __name__ == "__main__":
po = multiprocessing.Pool(4)
for i in range(10):
po.apply_async(worker, args=(i,))
print("main process starting....")
po.close()
po.join()
print("main process stoping....")
''' 输出
main process starting....
0 is now running, process id: 3436
1 is now running, process id: 3437
2 is now running, process id: 3438
4 is now running, process id: 3436
3 is now running, process id: 3439
5 is now running, process id: 3437
6 is now running, process id: 3438
7 is now running, process id: 3436
8 is now running, process id: 3437
9 is now running, process id: 3439
main process stoping....
'''
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
使用进程池的优点提现在
限制同一时间进程并行的数目 多进程可以提高程序运行的效率,但是过多的进程切换反而会降低效率。原因是a.进程会占用计算机资源,资源决定了进程不能开启过多。b.进程的切换开销比较大,占用过多CPU资源。
进程池减少不必要的创建,销毁过程。
程序中,Pool(4) 的进程号只有 3436,3437,3438,3439 这四个进程号。证明进程池省去了创建和销毁的过程。
当进程数和计算机的内核数一致的时候,效率最高。我们可以先看看自己计算机的内核个数,使用 os.cpu_count() 或者 multiprocess.cpu_count() 来查看内核个数。
如果不填写内核参数,Pool 默认采取机器的内核个数。
from multiprocessing import Pool
p = Pool(4)
for i in range(5):
p.apply_async(f, args=(i,)) # 异步调用
p.apply(f, args=(i,)) # 同步调用
p.close()
p.join()
2
3
4
5
6
7
# 构造方法
class multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
# 一个进程池对象,它控制可以提交作业的工作进程池。它支持带有超时和回调的异步结果,以及一个并行的 map 实现。
2
- processes 进程数,默认采用
os.cpu_count() - initializer(*initargs) 进程池调用前的初始化方法
# 方法
apply(func[, args[, kwds]])
返回结果前阻塞。这种情况下,
apply_async()(opens new window) 更适合并行化工作。另外 func 只会在一个进程池中的一个工作进程中执行。apply_async(func[, args[, kwds[, callback[, error_callback]]]]) 非阻塞操作
callback 是一个只接受一个参数的可调用对象。成功则执行callback,失败执行 error_callback
map(func, iterable[, chunksize])
内置函数
map的并行版本,map会 保持阻塞 直到获得结果。iterable 可以切分成多块运行,chunksize 指定块的大小。
当 iterable 太大的时候,为了节省内存,可以使用 imap 和 imap_unordered
map_async(func, iterable[, chunksize[, callback[, error_callback]]])
map 的对应的异步回调方法
imap(func, iterable[, chunksize] 需要显式的设置 chunksize,可以极大的加快 map 的速度。原先map中的默认值为1。
imap_unordered imap 的无序版本
apply_async 和 map_async 除了是异步执行的以外,它们还会放回一个 AsyncResult 对象,它有如下方法
- get([timeout]) 获取执行的结果
- wait([timeout]) 阻塞,直到返回结果
- ready 是否已完成结果
- successful 是否已完成且没有发生异常
# 进程间通信——数据传递
multiprocessing 支持两种通信方式:Queue(队列) , Pipe(管道)
# 基础用法
q = Queue(maxsize=4)
q.put(obj, block=True, timeout=None) # 存入队列中
q.get(obj, block=False) # 读取队列
# block: 是否主动阻塞,阻塞的时间为timeout。timeout=None 代表一直阻塞。block为 False 的时候,会主动抛出 queue.Full 和 queue.Empty 的错误。
# Pipe 建立的是一个双全工的连接
parent_conn, child_conn = Pipe()
parent_conn.send([42, None, 'hello']) # 发送
parent_conn.close() # 关闭 一端的连接,关闭后不可以再次进行 send 和 recv 操作
child_conn.recv() # 接收
2
3
4
5
6
7
8
9
10
可以看出,Pipe 是只能在两个进程进行通信,而 Queue 可以支持多个队列。Pipe 解决了进程之间的通信问题,Queue 还加上了一个缓冲区的作用。
那么multiprocessing.Queue 和 标准库中的 queue 的区别是什么?
- 需要注意的是这里是多进程编程,进程是资源分配的最小单位。不同的进程是无法获取对方堆栈的。Queue 可以解决这一个数据共享的问题。如果我们现在采用的是多线程编程,那么就可以直接采用标准库的queue 来替代。
- multiprocessing 中的 Queue 实现了标准库中的 queue 中的所有方法,除了
task_done和join方法
# Pipe 的使用
conn1, conn2 = multiprocessing.Pipe([duplex])
# 返回 Connection 对象 conn1,conn2 分别代表管道的两端。Connection 类型
while conn1.poll():
conn1.recv()
2
3
4
duplex: True 代表双全工,即管道的两端是可以双向的通信的。False 代表单向, conn1 只能用于接收消息,而 conn2 仅能用于发送消息。
Connect 对象的方法有
send/recv 发送的对象必须是可序列化的
send_bytes(buffer[, offset[, size]]) / recv_bytes([maxlength]) /
recv_bytes_into(buffer[, offset])发送 和 接受 bytes-like object (opens new window) 字节类对象
poll([timeout]) 返回连接对象中是否有可以读取的数据
close() 关闭
注意的一点是,Connect 的仅仅支持少量数据的发送,对于多大的对象(32M+),可能会引发异常
# Queue 的使用
class multiprocessing.Queue([maxsize])
主要实现了如下属性&方法,基本和 queue 一样
qsize 队列大小,由于是多进程的上下文,这个数字不是很可靠,而且在Mac OS X 上可能存在异常。
empty 是否为空
full 是否为满
put(obj[, block[, timeout]]) 当没有可用缓冲槽的时,抛出
queue.Empty(opens new window) 异常put_nowait(obj) 等价于 put(obj, False)
get([block[, timeout]]) 当没有可取用对象时,抛出
queue.Empty(opens new window) 异常get_nowait() 等价于 get(False)
close() 指示当前进程将不会再往队列中放入对象
# Queue的几种变形
multiprocessing.SimpleQueue() 简化的队列,其只具有empty、get、put3个方法。
这个队列实际上是用 Pipe 实现的
multiprocessing.JoinableQueue(maxsize=0) 建立可阻塞的队列实例,采用一般队列的方式访问。加上了
join和task_done两个方法。
# 进程间通信——数据共享
进程间的通信 Pipe 和 Queue 能解决小批量数据的传输,如 Pipe.send() 方法发送的数据一般不超过 32M。对于大量的数据,可以借助 共享内存 和 Manager 类实现。Manager实现了两个重要的类型 list 和 dict。
# Manager 类(共享进程)
import multiprocessing
import time
def f(list, x):
print(list, x)
list.append(x)
if __name__ == '__main__':
manager = multiprocessing.Manager()
mag_list = manager.list([])
with multiprocessing.Pool(4) as p:
for item in [1, 2, 3]:
p.apply(f, args=(mag_list, item))
p.close()
print(mag_list)
# output:
# [] 1
# [1] 2
# [1, 2] 3
# [1, 2, 3]
# 可以尝试 mag_list=[] ,最后的结果是不会发生任何变化
# [] 1
# [] 2
# [] 3
# []
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# Value, Array(共享内存)
multiprocessing.Value(typecode_or_type, *args, lock=True)
multiprocessing.Array(typecode_or_type, size_or_initializer, *, lock=True)
2
typecode_or_type 类型码
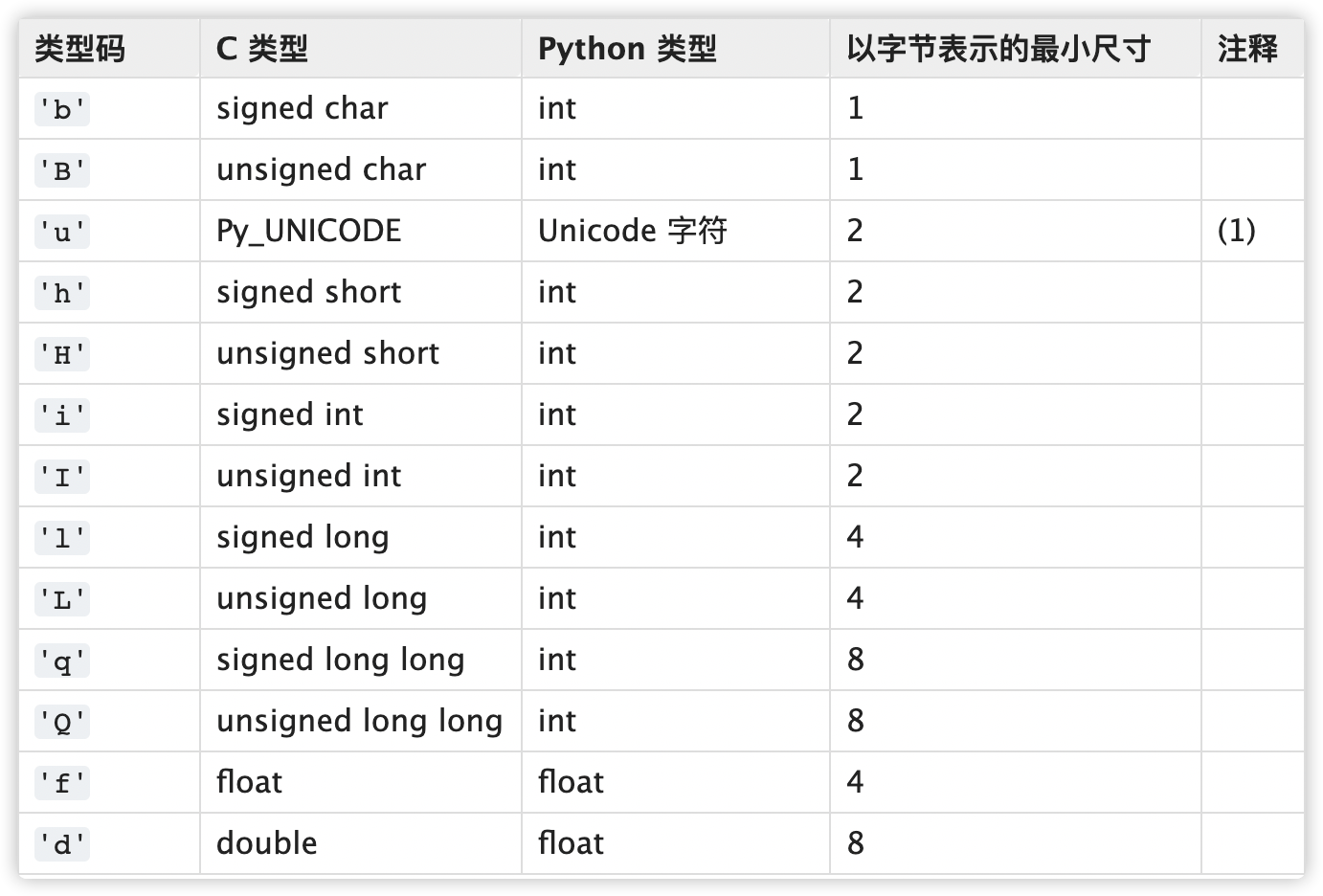
size_or_initializer 大小,或者初始化操作
multiprocessing.Array('i', 3) # 结果 [0,0,0] multiprocessing.Array('i', range(3)) # 结果 [0,1,2]1
2Lock 锁操作,在修改访问数据的时候,通过设置为 True 能锁定资源,阻塞其他进程的访问。
# 例子
v = multiprocessing.Value('d', 10, lock=True)
with v.get_lock(): # 修改值前,加锁
v.value += 1 # 属性 value 取值
2
3
# 数据进程锁
上一部分解决了进程间共享数据的操作。但是不同进程若是需要对于共享数据进行修改,可能会发生冲突。解决这一类问题的方式就是在 重要数据修改的时候加上锁,修改完毕再释放。
multiprocessing 的 互斥&同步操作有: Lock, Semaphore , Event 和 Barrier
# Lock 原始锁
原始锁(非递归锁)对象,一旦一个进程或者线程拿到了锁,后续的任何其他进程或线程的其他请求都会被阻塞直到锁被释放。任何进程或线程都可以释放锁。
Lock 一般只针对一个资源同步访问
# RLock 递归锁
**递归锁必须由持有线程、进程亲自释放。**递归锁和原始锁的区别是,一个进程可以多次加锁,每次加锁,锁加一。每次释放,锁减一。所以当获得锁和释放锁的数量相等的时候,才能释放锁住的资源。使用方法和Lock 一样。
# Semaphore 信号量
Semaphore 一般是针对多个(有限)资源的访问的,它的操作和Lock一样。只是初始化的时候,需要给出型号量的初始值。可以认为Semaphore(1) 和 RLock是相同的。
上面三个锁的使用方法都可以使用 acquire/release 操作
# Barrier 屏障
当若干个进程没有到达屏障点的时候,会自动阻塞,一旦到达屏障点,将会自动解除阻塞并启动运行
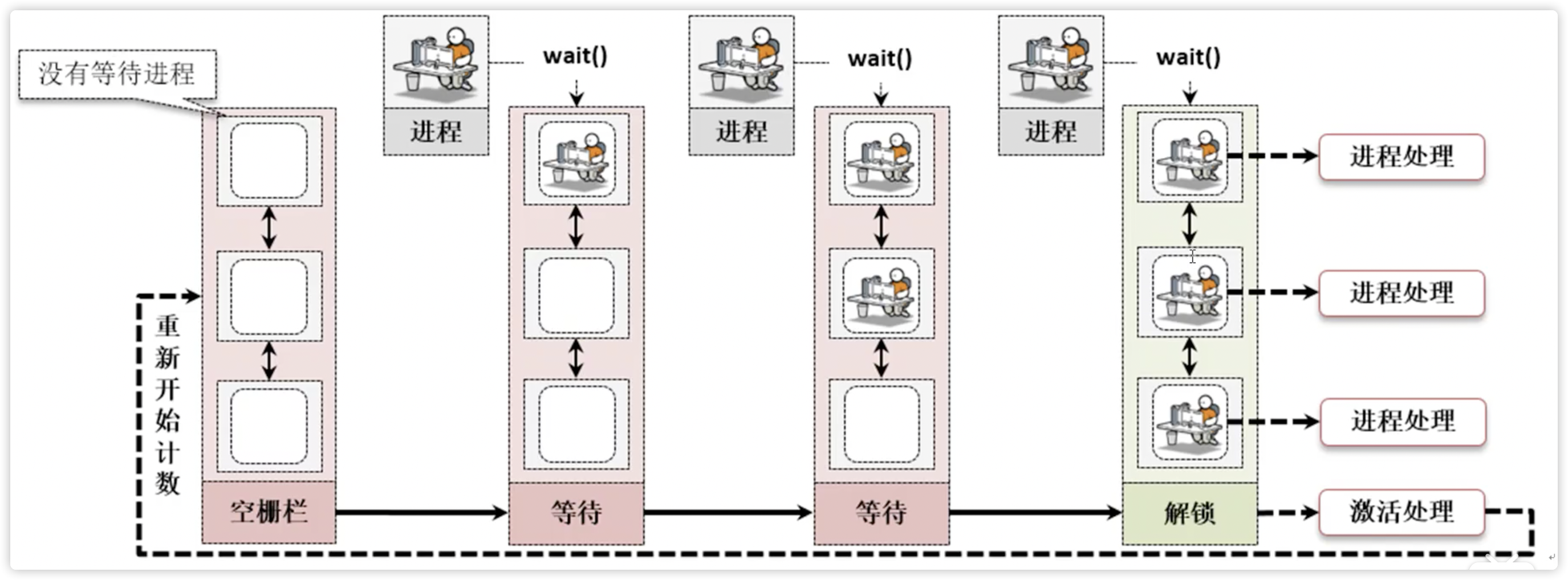
class threading.Barrier(parties, action=None, timeout=None)
- parties 栅栏的个数
- action 当突破栅栏后,会在被释放的其中一个进程中运行
# 属性
- n_waiting 当前时刻正在栅栏中阻塞的线程数量。
- broken 值为
True表明栅栏为破损态。
# 方法
- wait(timeout=None) 阻塞操作,函数会返回一个范围在 0~parties-1 内的整数。当为0 的时候,代表栅栏破裂
- reset() 重置为初始状态
- abort() 与reset() 相反,设置为破损状态
# Event 事件锁
这是线程之间通信的最简单机制之一:一个线程发出事件信号,而其他线程等待该信号。
# 方法
- is_set() 判断内部标识位是否为True
- set() 设置内部标识位为True
- clear() 设置内部标识位为False
- wait() 阻塞线程直到内部变量为true。如果调用时内部标志为true,将立即返回。否则将阻塞线程,
# 例子
由于之前没有接触过Event,这里自己练手写了一个Event 的小例子。
import multiprocessing
import time
def car(e, car_id):
print(f'car {car_id} is coming ')
if not e.is_set():
print(f'car {car_id} is waiting')
e.wait()
if e.is_set():
print(f'car {car_id} pass the cross road')
def traffic_light(e):
"""
红绿灯切换的时候,e.clear 和 e.set 是成队出现的。
因为红绿本省就是相互同步的一个操作
"""
while True: # 每5秒切换一次红绿灯
if e.is_set():
time.sleep(2)
print('<<<<<<<<<<<<<<< green to red >>>>>>>>>>>>>>>>>>>')
e.clear()
if not e.is_set():
time.sleep(2)
print('<<<<<<<<<<<<<<< red to green >>>>>>>>>>>>>>>>>>>')
e.set()
if __name__ == '__main__':
event = multiprocessing.Event()
event.clear() # 默认设置红灯
cars = [multiprocessing.Process(target=car, args=(event,car_id)) for car_id in range(10)]
lights = multiprocessing.Process(target=traffic_light, args=(event,))
lights.daemon = True # 设置完这一步,可以在小汽车都开走后,结束整个程序。
lights.start()
for each in cars:
each.start()
time.sleep(1) # 间隔一秒钟发车
for each in cars:
each.join()
# 当 each.join 执行完毕,此时 traffic_light 还在后台运行
# 但是由于没有添加 traffic_light.join() 所以此时 mian 结束,带着守护进程 traffic_light一起结束
# 输出结果如下
car 0 is coming
car 0 is waiting
car 1 is coming
car 1 is waiting
<<<<<<<<<<<<<<< red to green >>>>>>>>>>>>>>>>>>>
....
<<<<<<<<<<<<<<< green to red >>>>>>>>>>>>>>>>>>>
car 8 is coming
car 8 is waiting
car 9 is coming
car 9 is waiting
<<<<<<<<<<<<<<< red to green >>>>>>>>>>>>>>>>>>>
car 8 pass the cross road
car 9 pass the cross road
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
如果我们不启动守护进程,而是一直让程序在后台运行。这样我们可以感受到 守护进程 的作用
cars = [multiprocessing.Process(target=car, args=(event,car_id)) for car_id in range(10)]
lights = multiprocessing.Process(target=traffic_light, args=(event,))
- lights.daemon = True # 设置完这一步,可以在小汽车都开走后,结束整个程序。
lights.start()
for each in cars:
each.start()
time.sleep(1) # 间隔一秒钟发车
for each in cars:
each.join()
+ lights.join() #
# 输出结果如下
<<<<<<<<<<<<<<< red to green >>>>>>>>>>>>>>>>>>>
car 9 pass the cross road
car 8 pass the cross road
<<<<<<<<<<<<<<< green to red >>>>>>>>>>>>>>>>>>>
<<<<<<<<<<<<<<< red to green >>>>>>>>>>>>>>>>>>>
<<<<<<<<<<<<<<< green to red >>>>>>>>>>>>>>>>>>>
<<<<<<<<<<<<<<< red to green >>>>>>>>>>>>>>>>>>>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Condition 条件锁
# 几种方法的比较
| 方法 | 名称 | 作用 |
|---|---|---|
| Lock | 原始锁 | 当多个进程需要访问共享资源的时候,、 |
| RLock | 递归锁 | Lock 的升级 |
| Semaphore | 信号量(计数器锁) | Semaphore用来控制对共享资源的访问数量,例如池的最大连接数。 |
| Barrier | 时间锁 | 进程间同步通信 |
| Barrier | 障碍锁 | 等待足够资源启动 |
# 参考资料
B站【李兴华编程训练营】Python并发编程 (opens new window)
知乎python并行计算(上):multiprocessing、multiprocess模块 (opens new window)